Hyunjung Im
Frontend Developer

Go와 Node.js에서 동시성 작업을 처리하는 방법 01 - Node.js
2023-03-03

멀티 스레드 기반의 서버는 일반적으로 클라이언트의 요청마다 스레드를 생성합니다. 동시 접속자 수가 많을수록 스레드가 많이 생성된다는 의미이며 그만큼 메모리 자원도 많이 소모하게 됩니다. 그리고 스레드가 작업을 수행할 때 공유 자원을 사용할 권한을 기다리게 되면서 병목 현상이 발생할 가능성도 많습니다.
이 병목을 해결하는 방법은 프로세스 혹은 스레드를 대기 상태로 두지 않고 계속 일을 시키는 방법인데 대표적으로 Node.js의 이벤트 루프와 Go의 고루틴이 있습니다.
Node.js와 Go는 스레드를 생성하여 동시성을 처리하는 다른 언어들과는 다르게 동시성을 처리한다는 공통점이 있습니다. Node.js는 싱글 스레드를 사용하고 Go는 경량 스레드라고 하는 고루틴을 생성하여 사용합니다.
Node.js와 Go가 어떤 방법으로 동시성을 처리하는지 함께 알아보면 좋을 것 같아 정리해보았습니다. (커널, I/O모델, 시스템 콜에 대한 설명이 필요없다면 Node.js 여기서부터 보시면 됩니다.)
(제가 정리한 것 중에 틀린 점이 있다면 꼭 알려주세요~)
목차
- Kernel 커널
- I/O 작업
- 시스템 콜 (System Calls)
- I/O 모델
- Node.js
- Node.js에서는 I/O 처리를 어디에서 할까?
- 이벤트 루프
- Node.js의 스레드
- Libuv
- Node.js의 장점
- Node.js의 단점
Kernel 커널
커널은 무엇일까요?

커널은 간단하게 말해서 컴퓨터에서 항상 실행되는 프로그램을 의미합니다. 운영체제의 핵심적인 부분입니다.
커널의 역할은 무엇일까요?
커널은 하드웨어와 응용 프로그램 사이에서 인터페이스를 제공하는 역할을 하며 컴퓨터 자원들을 관리하는 역할을 합니다. 응용 프로그램 수행에 필요한 여러 가지 서비스를 제공하고, 여러 가지 하드웨어(CPU, 메모리) 등의 리소스를 관리하는 역할을 합니다.
그리고 추상화 역할도 합니다. 컴퓨터에서 사용하는 하드웨어의 종류는 다양합니다. 하지만 컴퓨터에서 실행되는 프로그램들은 어떤 부품을 사용하는지 일일이 알기 힘듭니다. 그래서 커널은 하드웨어 자원의 다양함을 신경 쓰지 않고 응용 프로그램에게 같은 서비스를 제공해주는데, 이것을 하드웨어 추상화(Hardware Abstraction Layer)라고 합니다.
커널이 물리적 자원을 추상화하며 용어가 달라집니다.
- CPU →
task - Memory →
page,segment - Disk →
file - Network →
socket
이러한 커널은 항상 컴퓨터 자원들을 바라만 보고 있기에 사용자와의 상호작용은 지원하지 않아요. 따라서 사용자와의 직접적인 상호작용을 위해 시스템 프로그램을 제공하게 되는데, 대표적으로 쉘(Shell)이라는 명령어 해석기 등이 있습니다.
맥북에서 Open Activity Monitor(활성 상태 보기)를 클릭해서 제일 스레드가 많은 프로세스를 보면 kernel_task가 있을 거에요. (DeepL.. 부끄럽군용)

커널은 전반적으로 CPU 과부하를 방지하고 시스템을 안정시키기 위해 일합니다. CPU에 과부하 등의 문제가 발생하면 kernel이 프로세스나 스레드의 재분배를 통해 시스템을 정리하고 문제를 해결합니다.
운영체제의 주요 기능인 자원 관리, 자원 스케줄링 기능, 사용자와 시스템 간의 편리한 인터페이스 제공, 하드웨어와 네트워크 관리 제어 이 대부분의 기능은 커널이 담당합니다. 그래서 운영체제 === 커널 이라고 하는 경우도 많습니다.
I/O 작업
Input/Output의 약자로 주로 파일 입출력을 다룰 때 흔히 볼 수 있습니다. 파일 입출력에만 국한된 것은 아니고 네트워크 연결 시에도 I/O 작업이 이뤄집니다.
I/O 작업은 컴퓨터의 기본 작업 중에 제일 느립니다. 이 작업을 어떻게 처리하느냐에 따라 서비스의 성능이 달라지게 됩니다.
I/O 작업은 어디서 이뤄질까요?
실제 I/O 작업을 수행하는 것은 Kernel에서만 가능합니다. 유저 프로세스(또는 스레드)는 커널에게 요청을 하고 작업 완료 후 커널이 반환하는 결과를 기다릴 뿐입니다.
여기서 커널에게 요청을 하는 것을 시스템 콜 이라고 합니다. 밑에서 더 설명할게요.
시스템 콜 (System Calls)
우리가 일반적으로 사용하는 프로그램은 응용프로그램이죠. 이 프로그램을 유저 레벨 프로그램(또는 고급 언어로 작성된 프로그램)이라고 하는데, 유저 레벨 프로그램에서 I/O작업을 해야할 때 커널의 도움을 반드시 받아야 합니다. 커널에 관련된 것은 커널 모드로 전환한 후에야 해당 작업을 수행할 권한이 생기기 때문에 커널에 허락을 구해야 합니다. 이 허락을 구하는 수단을 시스템 콜이라고 합니다.
간단히 말해 응용 프로그램의 요청으로 커널에 접근하기 위한 인터페이스를 말합니다. 운영체제 서비스를 이용하기 위한 수단입니다.
I/O 모델
I/O 모델은 5가지가 있습니다.
- Blocking I/O
- Non Blocking I/O
- I/O Multiplexing
- Signal Driven I/O
- Asynchronous I/O
우리는 1번 ~ 2번 방법을 살펴보겠습니다. 이유는 Node.js와 Go가 기본적으로 Non Blocking 방식을 사용하기 때문입니다.
Blocking I/O
가장 기본적인 I/O 모델입니다. linux에서 모든 소켓 통신은 기본 Blocking I/O로 동작합니다.
I/O 작업이 진행되는 동안 유저 프로세스는 자신의 작업을 중단한 채 대기하는 방식입니다.
Non Blocking I/O
위와 같은 Blocking 방식의 비효율성을 극복하고자 도입된 방식입니다.
I/O 작업이 진행되는 동안 유저 프로세스의 작업을 중단시키지 않는 방식입니다.
이제 기본적으로 알아야 할 것에 대해 설명했습니다. 본격적으로 Node.js와 Go에 대해 알아볼게요.
Node.js

Node.js는 싱글 스레드 논블로킹 모델로 효율적으로 자원을 사용하는 언어라고 알려져있습니다.
기존 멀티스레드 기반에서 벗어나 노드에서는 서버와 클라이언트의 연결을 하나의 이벤트로 처리합니다.
Javascript의 런타임 중 하나이고, 크롬의 핵심인 V8 js 엔진을 브라우저 외부에서 실행합니다.
Node.js는 표준 라이브러리에서 JavaScript 코드가 차단되지 않도록 하는 비동기 I/O 프리미티브 세트를 Libuv를 통해 제공하며 일반적으로 Node.js의 라이브러리는 non-blocking 패러다임을 사용하여 작성됩니다.
이벤트 루프와 Libuv에 대해서는 밑에서 더 설명하겠습니다.
Node.js에서의 Blocking I/O 방식
Node.js는 기본적으로 Non Blocking 방식이지만 Blocking 방식도 적용할 수 있습니다.
Node.js 메서드 중에 sync가 붙어있는 메서드를 보신 적 있으실 거에요. sync의 의미가 Blocking 방식을 의미합니다. 기본적으로는 Non blocking 방식을 사용하기 때문에 sync 를 붙여 blocking 동작을 표준이 아닌 예외로 만드는 거에요.
Blocking은 Node.js 프로세스에서 추가 자바스크립트 실행이 자바스크립트가 아닌 작업이 완료될 때까지 기다려야 하는 경우입니다. 이는 Blocking 작업이 진행되는 동안 이벤트 루프가 JavaScript를 계속 실행할 수 없다는 의미에요.
I/O와 같은 작업이 아닌 CPU 집약적이기 때문에 성능이 저하되는 Javascript(시간복잡도 등으로 비용이 큰 작업 같은 것들)를 일반적으로 Blocking이라고 부르지는 않아요.
Node.js 표준 라이브러리의 sync 동기 메서드가 가장 일반적으로 사용되는 Blocking 연산입니다.
const fs = require("fs");
const data = fs.readFileSync("/file.md"); // blocks here until file is readconst fs = require("fs");
fs.readFile("/file.md", (err, data) => {
if (err) throw err;
});첫 번째 예제는 두 번째 예제보다 간단해 보이지만 두 번째 줄이 전체 파일을 읽을 때까지 추가 JavaScript 실행을 차단하는 단점이 있습니다 . 동기식 버전에서는 오류가 발생하면 이를 잡아야 하며 그렇지 않으면 프로세스가 중단됩니다. 비동기 버전에서 표시된 대로 오류를 발생시켜야 하는지 여부는 작성자가 결정합니다.
보통의 경우 sync 메서드를 쓸 일은 잘 없습니다. 거기다 sync 메서드와 논블로킹 메서드를 함께 쓰면 위험 요소가 많아집니다.
Blocking와 Non-Blocking Code를 혼합했을 때 발생하는 위험 설명 보기 click!
Blocking와 Non-Blocking Code를 혼합했을 때 발생되는 위험
const fs = require("fs");
fs.readFile("/file.md", (err, data) => {
if (err) throw err;
console.log(data);
});
fs.unlinkSync("/file.md");위의 예제에서 fs.unlinkSync()는 fs.readFile()보다 먼저 실행될 가능성이 높으며, 이로 인해 file.md가 실제로 읽히기 전에 삭제될 수 있습니다. 완전히 차단되지 않고 올바른 순서로 실행되도록 보장하는 더 나은 작성 방법은 다음과 같습니다:
const fs = require("fs");
fs.readFile("/file.md", (readFileErr, data) => {
if (readFileErr) throw readFileErr;
console.log(data);
fs.unlink("/file.md", (unlinkErr) => {
if (unlinkErr) throw unlinkErr;
});
});위는 fs.readFile()의 콜백 내에 fs.unlink()에 대한 비차단 호출을 배치하여 올바른 작업 순서를 보장합니다.
Node.js의 JavaScript 실행은 단일 스레드이므로 동시성은 다른 작업을 완료한 후 JavaScript 콜백 함수를 실행하는 이벤트 루프의 용량을 나타냅니다. 동시 방식으로 실행될 것으로 예상되는 모든 코드는 I/O와 같은 비JavaScript 작업이 발생할 때 이벤트 루프가 계속 실행되도록 허용해야 합니다.
예를 들어, 웹 서버에 대한 각 요청을 완료하는 데 50ms가 걸리고 그 50ms 중 45ms가 비동기적으로 수행될 수 있는 데이터베이스 I/O인 경우를 생각해 봅시다. 예를 들어, 웹 서버에 대한 각 요청을 완료하는 데 50ms가 걸린다고 가정해보겠습니다.
- 50ms 중 45ms가 비동기적으로 수행될 수 있는 데이터베이스 I/O라면?
→ 요청당 45ms를 확보하여 다른 요청을 처리할 수 있습니다. - Blocking방법을 적용해야 한다면?
→ 요청 2개를 보낸다면 90ms가 걸리고, 각 요청을 처리할 때 다른 요청을 처리할 수 없습니다.
Blocking 방식 이 아닌 Non Blocking 방식을 선택하는 것만으로도 상당한 용량 차이가 납니다.
Node.js에서는 I/O 처리를 어디에서 할까?
Node는 기본적으로 I/O 관련 작업을 멀티 스레드 구조로 이루어진 OS 커널 혹은 Libuv의 thread pool에서 처리합니다.
분명 Node.js는 싱글 스레드라고 했는데, 멀티 스레드라고 나오니 조금 의아할 수도 있을 거에요. 이에 대한 답은 이벤트 루프에 있습니다.
이벤트 루프
이벤트 루프는 사실 일반적인 프로그래밍 패턴을 지칭하는 용어입니다.
컴퓨터 과학에서 이벤트 루프(event loop), 메시지 디스패처(message dispatcher), 메시지 루프(message loop), 메시지 펌프(message pump), 런 루프(run loop)는 프로그램의 이벤트나 메시지를 대기하다가 디스패치(효율적으로 처리)하는 프로그래밍 구조체이다.
js에서 이벤트 루프는 다른 말로 메인 루프, 메인 스레드, 이벤트 스레드라고 불립니다. 기본적으로 이벤트 루프를 메인 스레드로 활용하기 때문에 싱글 스레드라고 말합니다. 하지만 모든 처리를 스레드 하나로 처리하는 것은 아닙니다. 파일 I/O와 같은 값비싼 작업은 다른 곳에 offload합니다. (offload는 일반적으로 비동기적으로 실행되는 작업을 외부 리소스나 프로세스에 맡기는 것을 의미합니다.)
이벤트 루프는 자바스크립트가 싱글 스레드임에도 불구하고 가능한 경우 시스템 커널로 작업을 오프로드하여 비차단 I/O 작업을 수행할 수 있게 해주는 기능입니다.
실제로 노드 애플리케이션에서 진행되는 모든 것은 이벤트 루프를 통해 실행됩니다.

Morning Keynote- Everything You Need to Know About Node.js Event Loop - Bert Belder, IBM
이 발표에서 Bert Belder는 node js event loop를 검색했을 때 나오는 이미지 결과들은 거의 틀렸다고 말합니다. (이미지를 볼 때 맞는 것인지 잘 유의해서 봐야합니다.)
브라우저의 이벤트 루프와 Node.js의 이벤트 루프는 같을까?
크롬 브라우저는 libevent를 Node.js는 libuv를 각각 이벤트 루프 구현을 위해 사용합니다. 브라우저와 Node.js의 이벤트루프는 기본적으로 다른 라이브러리를 사용하여 약간의 차이가 있을 수 있을 수 있지만 이벤트루프라고 하는 일반적인 프로그래밍 구조체를 구현하고 있다는 것에서 비슷하다고 할 수 있습니다.
그리고 대표적인 잘못된 개념들 중 하나는 바로 이벤트 루프가 Javascript 엔진의 일부라는 것입니다. 이벤트 루프는 단지 Javascript 코드를 실행하기 위해 자바스크립트 엔진을 이용하기만 할 뿐입니다.
Node.js의 스레드
Node.js에는 두가지 유형의 스레드가 있습니다.
- 이벤트 루프
- Worker Pool (일명 스레드 Pool이라고 합니다.)
이 두 가지 모두 Libuv를 통해 제공됩니다.
Libuv
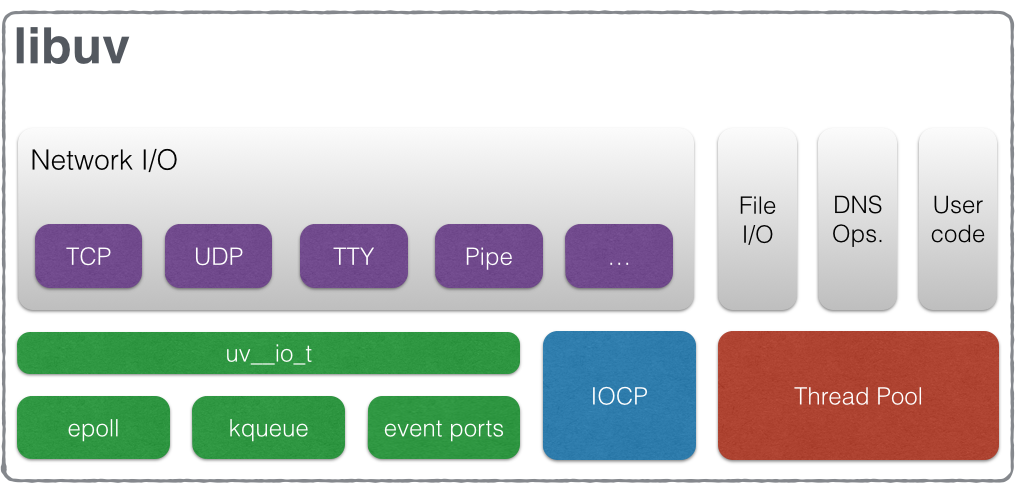
Node.js는 기본적으로 Libuv 위에서 동작하며, node 인스턴스가 실행될 때 Libuv는 워커 풀(스레드 풀)에 4개의 스레드를 생성합니다. 이벤트 루프에 사용되는 스레드 외에도 응용 프로그램 내부에서 발생해야 하는 비용이 많이 드는 계산을 오프로드 하는 데 사용할 수 있는 4개의 다른 스레드가 있습니다.
http 요청을 하는 경우 libuv는 이를 확인하고 네트워크 요청과 관련된 모든 초 저수준 작업을 처리할 코드가 없습니다. 대신 libuv는 운영 체제에 http 요청을 위임합니다.
Libuv는 기본 운영 체제에 작업을 위임합니다. 그런 다음 운영 체제는 사용자가 듣고 있는 이벤트가 발생할 때 알림을 보내는 역할을 합니다. 그러나 모든 것을 기본 OS에 위임할 수 있는 것은 아닙니다. 때때로 스레드를 생성해야 합니다. 파일 시스템 작업, dns.lookup() 및 일부 암호화 기능은 폴링할 수 없어요. 밑 어떤 코드가 Worker Pool에서 동작하는가?를 참고하세요.
이벤트 루프의 내부 동작 과정
┌───────────────────────────┐
┌─>│ timers │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ Call pending callbacks │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ idle, prepare │
│ └─────────────┬─────────────┘ ┌───────────────┐
│ ┌─────────────┴─────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └─────────────┬─────────────┘ │ data, etc. │
│ ┌─────────────┴─────────────┐ └───────────────┘
│ │ check │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │
└───────────────────────────┘이 다이어 그램은 이벤트 루프의 작업 순서에 대한 간략한 개요를 보여줍니다.
| timers | 이 단계는 setTimeout() 및 setInterval()에 의해 예약된 콜백을 실행합니다 |
| call pending callbacks | 다음 루프 반복으로 연기된 I/O 콜백을 실행합니다. 여기에서 대부분의 콜백이 처리됩니다. Node.js의 모든 사용자 영역 코드는 기본적으로 콜백에 있기 때문에(예: 들어오는 http 요청에 대한 콜백이 일련의 콜백을 트리거하는 경우) 이것이 바로 userland 코드입니다. |
| idle, prepare | 내부적으로만 사용됩니다. |
| poll | 새로운 I/O 이벤트를 검색하고, I/O 관련 콜백을 실행합니다.(close 콜백, 타이머에 의해 예약된 콜백, setImmediate()를 제외한 거의 모든 콜백 노드는 적절한 경우 여기서 차단합니다. |
| check(Set Immediate) | setImmediate()을 통해 등록된 모든 콜백을 실행합니다. |
| close callbacks | 여기서 모든 on(‘close’) 이벤트 콜백이 처리됩니다. 예: socket.on('close', ...) |
어떤 코드가 이벤트 루프에서 동작하는가?
이벤트 루프는 이벤트에 등록된 JavaScript 콜백을 실행하고 네트워크 I/O와 같은 비차단 비동기 요청을 이행하는 역할도 합니다.
이벤트 루프는 수행 도중에 Blocking I/O작업을 만나면 커널 비동기 또는 자신의 워커 풀에게 넘겨주는 역할도 합니다. 콜백 내부 로직, 분기 처리, 반복문 등은 이벤트 루프가 수행하지만 DB에서 데이터를 읽어오거나 외부 API콜을 하는 것은 커널 비동기 또는 워커 스레드가 수행합니다. 동시에 많은 요청이 들어온다고 해도 1개의 이벤트 루프에서 처리합니다.
app.get("/countToN2", (req, res) => {
let n = req.query.n;
// n^2 iterations before giving someone else a turn
for (let i = 0; i < n; i++) {
for (let j = 0; j < n; j++) {
console.log(`Iter ${i}.${j}`);
}
}
res.sendStatus(200);
});이 경우 On^2으로 연산 크기에 따라 이벤트 루프가 block될 수 있으므로 조심해야 합니다.
app.get("/redos-me", (req, res) => {
let filePath = req.query.filePath;
// REDOS
if (filePath.match(/(/.+)+$/)) {
console.log("valid path");
} else {
console.log("invalid path");
}
res.sendStatus(200);
});이 예제는 서버를 REDOS에 노출시키는 취약한 정규 표현식의 예입니다.
그리고 JSON.parse, JSON.stringify 또한 잠재적으로 비용이 많이 드는 작업입니다. 서버가 JSON을 조작하는 경우 데이터의 크기에 주의해야 해요.
어떤 코드가 Worker Pool에서 동작하는가?
Node.js는 워커 풀을 “값비싼” 작업을 처리하는 경우에 이용합니다. 해당 작업에는 CPU 집약적(CPU-intensive)인 작업들뿐만 아니라 OS에서 Non Blocking을 지원하지 않는 I/O의 경우도 포함됩니다.
비동기적인 모든 것은 워커 풀(스레드 풀)에 의해 처리되는 것은 아닙니다. 대부분의 최신 커널은 다중 스레드이기 때문에 백그라운드에서 실행되는 여러 작업을 처리할 수 있는 비동기 인터페이스가 있습니다.
가능할 때마다 Libuv는 위 비동기 인터페이스를 사용하여 스레드 풀 사용을 피합니다. 다른 방법이 없을 경우에만 워커 풀을 사용합니다.
Libuv의 워커 스레드는 커널이 지원하지 않는 작업들을 수행합니다. 대표적인 예로 소켓 작업류는 커널들이 이미 비동기로 지원하지만, 파일시스템쪽 작업은 지원하지 않아 이럴 때 Libuv의 스레드가 쓰입니다.
아래 목록은 워커 풀을 사용하게 하는 Node.js 모듈 API입니다.
- I/O-intensive
- DNS:
dns.lookup(),dns.lookupService() - File System:
fs.FSWatcher()와 libuv의 스레드 풀을 명백하게 동기적으로 사용하는 경우를 제외한 모든 파일 시스템 API.
- DNS:
- CPU-intensive
- Crypto:
crypto.pbkdf2(),crypto.scrypt(),crypto.randomBytes(),crypto.randomFill(),crypto.generateKeyPair() - Zlib: libuv의 스레드 풀을 명백하게 동기적으로 사용하는 경우를 제외한 모든
zlib API
- Crypto:
이벤트 루프의 콜백에 의해 위 목록 중 하나의 API가 호출되었을 때 이벤트 루프에서는 해당 API를 위해 Node.js C++ 바인딩에 들어가고 워커 풀에 작업을 요청하므로 셋업을 함에 있어 약간의 리소스가 사용될 수 있습니다. 하지만 이 리소스는 작업을 위한 전체 비용에 비하면 무시할 정도이며 이것이 이벤트 루프가 오프로딩한 이유입니다. Node.js는 워커 풀에 이러한 작업을 요청할 때 Node.js C++ 바인딩에서 해당하는 C++ 함수에 대한 포인터를 함께 제공합니다.
Node.js에서는 다음에 실행될 코드를 어떻게 결정하는가?
추상적으로 말하자면 이벤트 루프와 워커 풀에서는 각각 대기 중인 이벤트와 대기 중인 작업을 관리하기 위한 큐를 가지고 있습니다. (실제로는 이벤트 루프는 큐를 가지고 있지 않아요. 그 대신 이벤트 루프는 OS에게 모니터링을 요청하는 File descriptor들의 콜렉션을 가지고 있습니다.)
이 File descriptor들은 그것이 모니터링하고 있는 모든 네트워크 소켓, 모니터링 중인 파일 등과 작용합니다. OS에서 File descriptor가 준비되었다고 알리면 이벤트 루프에서는 이를 적절한 이벤트로 번역 후에 해당 이벤트에 관련된 콜백을 호출합니다.
이와 반대로 워커 풀에서는 진짜로 큐를 사용하여 처리할 작업의 입출입을 관리합니다. 하나의 워커는 하나의 작업을 해당 큐에서 pop해서 처리하며 작업이 완료되면 “최소한 하나의 작업은 끝났다”는 이벤트를 이벤트 루프에 보냅니다.
Node.js의 장점
Node.js 앱은 모든 요청에 대해 새 스레드를 생성하지 않고 단일 프로세스에서 실행됩니다. 멀티코어 컴퓨터에서 이는 로드가 모든 코어에 분산되지 않음을 의미하는데, Node가 제공하는 클러스터 모듈을 사용하면 CPU당 자식 프로세스를 쉽게 생성할 수도 있습니다.
Node.js로는 스레드 동시성 관리에서 자유롭습니다. 이벤트 루프를 이용해 동시성 관리 부담 없이 서버에서 수천 개의 동시 연결을 처리할 수 있다는 장점이 있습니다.
프런트엔드 개발자가 완전히 다른 언어를 배울 필요 없이 클라이언트 측 코드 외에도 서버 측 코드를 작성할 수 있기 때문에 고유한 이점이 있습니다.
Node.js에서는 모든 사용자가 브라우저를 업데이트할 때까지 기다릴 필요가 없으므로 새로운 ECMAScript 표준을 문제없이 사용할 수 있습니다.
Node.js의 단점
싱글 스레드가 Node.js의 단점이 될 수 있습니다. I/O작업은 효율적인 Non Blocking 메커니즘을 통해 처리되지만 CPU 집중적인 작업은 Blocking 방식으로 처리될 수밖에 없다는 것을 의미합니다.(복잡한 작업의 경우 작업을 Event Loop에서 Worker Pool로 옮길 수 있지만 오버헤드라는 단점이 있습니다.) Node.js 모델은 주요 성능 문제가 I/O 작업에서 발생할 경우에는 효율적으로 동작하지만, 만약 CPU 집중적인 코드가 끼어든다면 전체 요청 처리 속도를 심각하게 저하할 수 있습니다.

여기까지 읽으신 분이 계실까요? Node랑 Go 같이 정리하려는 생각을 했다니 참 바보같ㅇ..
이제 Go에 대해 알아볼게요.🚙
2탄에서 보아요.